Caching
Strategy, Control, Pattern
26 Jan 2019
View Comments
#computer
#programming
#cache
#caching
Caching can be extremely useful in a lot of applications. Caching allows you to reuse previously computed and fetched data. It even helps the program achieve unattainable product requirements. However, it could be a double-edged sword and haunt you instead because caches can mess up and have adverse effects on your application (such as OOM). That is why you would want to have the appropriate strategy which has good control over your “caches.”
Caches are not limited to software, in fact, chances are they are in every computing layer: OS, hardware, etc. Sometimes devices are explicitly built for caching purpose. For software, caches are typically saved locally meaning they take advantage of “fast” loading through the local server. You could technically design a cache served outside of the local server. However, this may introduce extra latency which defeats the entire purpose of having a cache.
When caches stored in the local server, they are often stored in hardware such as RAM (Random-access memory) to take advantage of faster write/access time. It is entirely possible to store and retrieve disk data, which has a significantly slower response time compared to memory, but you may gain the benefit of having a lot more space than memory. Generally, caches are meant to be short-term memory storage meaning it strives to have a small and “limited” space which usually keeps track of most recently accessed items (LRU).
Cache Invalidation
The idea of caching is great, but it’s not going to be valuable if cached items contain incorrect (wrong) data. That is why we need it frequently updated and managed. If not, it can cause some unexpected and inconsistent application behaviour.
Solving this type of problem is known as “cache invalidation.” To prevent such invalidations, we frequently categorize caches to different techniques. Here are the three techniques mainly in use these days. For these examples, I will assume cached data are for the database data.
- Write-through cache: Data goes into the cache, and that data is also going to the database. The cached data is beneficial upon fast access. This method will protect us from having inconsistent data or lost data. However, this scheme has higher latency in writes and cache can easily be flooded (unless we have appropriate eviction policy). Btw
Write-through cache 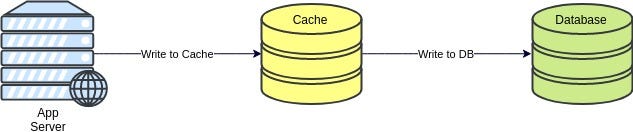
- Write-around cache: Similar to the above technique, but if we never seen this kind of data before, we write to the database only. We will avoid flooding cache with write operations which may not even reread in the future, but obviously, this also means we will have a lot of "cache miss" upon reading the data. It's generally useful when you have a lot of writes, but little reads.
Write-around cache 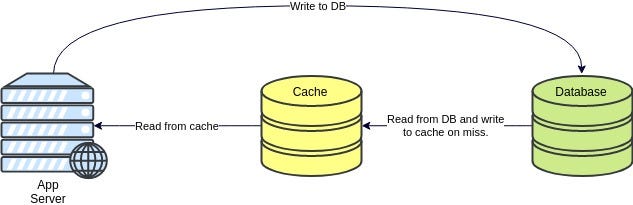
- Write-back cache: We store the data in cache instantly and notify clients (like how async works). Then permanent storage (to the database) is handled separately. It saves huge latency/response time but could risk data loss in case of a server crash (where cache resides) or other unexpected events because the cache is the only place that has this data. There are strategies to mitigate such issues.
Write-back cache 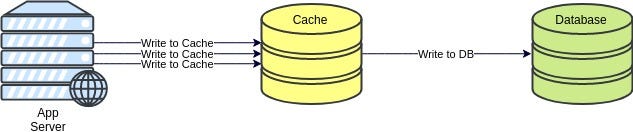
Cache Eviction Policies
Remember how I mentioned that cache size is to be “limited”? Cache eviction policies precisely handle such situations. The cached item(s) is released when the cached object(s) exceeds the quota to make up the space for the incoming new data. The process of releasing blocks is called eviction. The following are a couple of practiced eviction policies. However, from my experience, it is best to come up with a strategy for your application.
- First In First Out (FIFO, QUEUE): The cache evicts the first block accessed first regardless of any information about data (pretty dull)
- Last In First Out (LIFO, STACK): Removes the most recently accessed cache first irrespective of any information about data (pretty dull)
- Least Recently Used (LRU): Evicts the least recently used items.
- Most Recently Used (MRU): Evicts the most recently used items. (in contrast to LRU). MRU algorithms are most useful in situations where the older an item is, the more likely it is to be accessed
- Least Frequently Used (LFU): This one store counts of how often the item is needed. Evicts the lowest counts, meaning least commonly (frequently) used.
- Random Replacement (RR): Randomly selects a candidate item and discards it to make space when necessary (Not very useful)
Caching as Pattern
When we deal with caches, there are specific rules we generally follow to have them working. These rules later become a generic pattern most people follow.
Cache-Aside Pattern
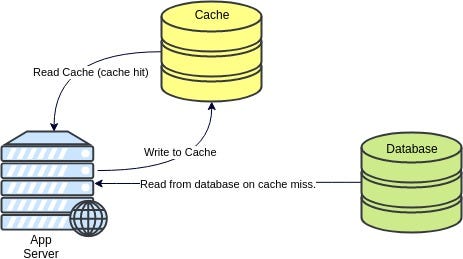 |
This pattern presumes the fundamental idea of caching. The application essentially works directly with the cache and see if the item exists in the cache. If not, fetch it from the data store and save the object in Cache.
Few issues may occur in applying this pattern though. All of these have already been discussed above. To reiterate:
- Lifetime of data: Should have expiry at some point.
- Data eviction: As described above, data should be able to control the cache size
- Consistency: We need to make sure the data in the cache consistent to what’s in the data store.
Flyweight Pattern
This pattern is well-known throughout the software industry for caching design pattern. However, a lot of people seem to be misunderstanding what it is. This pattern is very similar to Cache-Aside Pattern except that it deals with immutable data. It is essential to have the data immutable because those data ought to be shared between others.
There are many examples of flyweight. You could have a cache pool of a set of graphical representation unit, a set of connection pools, etc. The purpose is to save time calculating and generating such repetitive data.
While it is an excellent pattern for saving the amount of RAM usage, it can create messy and complicated codes.
