C.A.P.T.C.H.A.
Are you a human?
13 Oct 2018
View Comments
#captcha
#verification
#programming
#security

CAPTCHA is a verification method to determine whether a user is a real person or a bot. Most of us are probably familiar with this challenging images we had to answer to verify you are a human. I believe CAPTCHA is one of those things people know how to use it but not sure why we need to go through all the hassles. Let’s take a look at its history and “how-it-works”. By understanding all this, we can be sure why we need to fill these in and prevent us from potential vulnerability.
CAPTCHA is an acronym for Completely Automated Public Turing Test to Tell Computers and Humans Apart. A few people refer to it as “CAPTured CHAracter” (CAPTCHA). In 1999, there was a voting for choosing the best university for their scientific computer program. Students from some universities exploited the fact they could use bots to have a higher voting count. The results were fraud, manipulative and inaccurate. That’s when CAPTCHA had been gaining its popularity, and people started to apply it whenever some specific personal information collected.
CAPTCHA started as a pretty straightforward wiggly image like the one showing below. Bots would have had a tough time identifying which letter it is whereas a human can recognize it without much trouble. Back in the year 2000s, there weren’t any program that would distinguish which alphabets an image would show, so it was working quite effectively at the time.
 |
However, most of regular CAPTCHA had been tampered and hacked by many researchers. There had been many different attempts on variations to the traditional alphabet CAPTCHA, and we even attempted to show images other than wiggly alphabets. Our image processing and recognition were continuously getting better each day. According to the researchers, even those replaced-to-image-CAPTCHAs can be broken by bots 10-20% of the trials. You may think 10-20% a low success rate. However, considering how bots can execute a countless number of tries, aggregated successes will be incredibly high.
From the beginning, CAPTCHA had many controversies. It imposed a definite issue for visually impaired people because they obviously cannot get a pass through the CAPTCHA when they can’t see what it is!
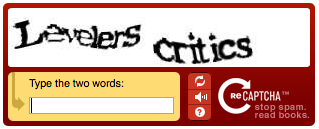 |
That’s when reCAPTCHA came into the market, with audio capability! Few researchers at Carnegie Mellon University first developed reCAPTCHA. They essentially processed all of New York Times archives from Google Books by completely digitizing them using OCR (Optical Character Recognition) software.
Google fancied the idea of reCAPTCHA and acquired it in 2009. However, there remained a fundamental issue, that the OCR process is pretty inaccurate. Few letters were not digitized correctly. That’s when Google decided to show a pair of text images like the image above. So in the above picture, one of the words represent a ‘clean’ word that Google knows what the word represents, and the other is a ‘dirty’ word, that they aren’t sure. Google expected if people successfully got the answer to ‘clean’ word, ‘dirty’ word must be correct as well. They collected all these answers and built their confidence to those ‘dirty’ words incrementally.
 |
Google was still stuck with the intrinsic problems that bots would start learning to be able to bypass the CAPTCHA and that humans naturally make human errors to make correct answers to the image. In the year 2014, Chinese researchers hacked reCAPTCHA v1. See video above for more detail. It wasn’t much sustainable around the time. In March 2018, Google had terminated usage of reCAPTCHA v1 entirely.
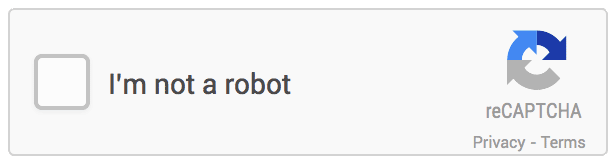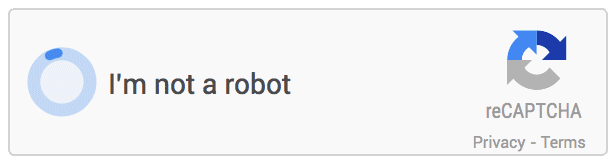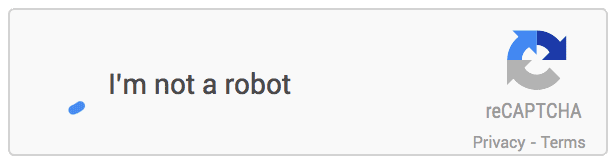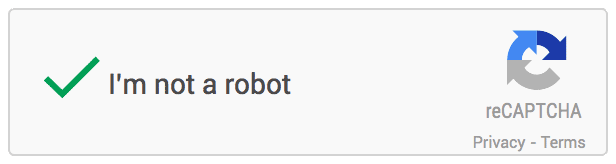
To alleviate all these problems, Google released NoCAPTCHA (reCAPTCHA v2) in 2014 by removing all of these verification steps unless you are deemed to be “suspicious”. If you are not “suspicious”, you are given a checkbox saying “I’m not a bot” to be validated. Google uses an iframe to determine whether you are a real person by collecting and analyzing your IP, loaded resources, cookies, your browsing history, etc. Theoretically, bots aren’t supposed to see anything related to reCAPTCHA at all when they approach the site with NoCaptcha (checkbox validation). For those “suspicious” users, they are usually prompted with additional images to verify as a human (like an image below).
 |
Google is developing yet another version of reCAPTCHA, version 3. It currently is in the beta version, but you can think of it as “invisible” reCAPTCHA. You won’t even see a checkbox any more instead there may be a little badge in the corner saying the page is using the reCAPTCHA. It is a JavaScript API which returns a score giving you the ability to take action in the context of your site: for instance, requiring additional factors of authentication. Version 3 still is not a bulletproof solution against the bots, but it at least stops them from bombarding continuous submits.
